Existem muitos algoritmos de compactação por perto e bzip2 é um dos mais lentos. O gzip simples tende a ser significativamente mais rápido, geralmente com compressão não muito pior. Quando a velocidade é a mais importante, lzop é o meu favorito. Má compressão, mas oh tão rápido.
Eu decidi me divertir e comparar alguns algoritmos, incluindo suas implementações paralelas. O arquivo de entrada é a saída do comando pg_dumpall em minha estação de trabalho, um arquivo SQL de 1913 MB. O hardware é um i5 quad-core mais antigo. Os tempos são tempos de relógio apenas da compressão. Implementações paralelas são configuradas para usar todos os 4 núcleos. Tabela classificada por velocidade de compactação.
Algorithm Compressed size Compression Decompression
lzop 398MB 20.8% 4.2s 455.6MB/s 3.1s 617.3MB/s
lz4 416MB 21.7% 4.5s 424.2MB/s 1.6s 1181.3MB/s
brotli (q0) 307MB 16.1% 7.3s 262.1MB/s 4.9s 390.5MB/s
brotli (q1) 234MB 12.2% 8.7s 220.0MB/s 4.9s 390.5MB/s
zstd 266MB 13.9% 11.9s 161.1MB/s 3.5s 539.5MB/s
pigz (x4) 232MB 12.1% 13.1s 146.1MB/s 4.2s 455.6MB/s
gzip 232MB 12.1% 39.1s 48.9MB/s 9.2s 208.0MB/s
lbzip2 (x4) 188MB 9.9% 42.0s 45.6MB/s 13.2s 144.9MB/s
pbzip2 (x4) 189MB 9.9% 117.5s 16.3MB/s 20.1s 95.2MB/s
bzip2 189MB 9.9% 273.4s 7.0MB/s 42.8s 44.7MB/s
pixz (x4) 132MB 6.9% 456.3s 4.2MB/s 7.9s 242.2MB/s
xz 132MB 6.9% 1027.8s 1.9MB/s 17.3s 110.6MB/s
brotli (q11) 141MB 7.4% 4979.2s 0.4MB/s 3.6s 531.6MB/s
Se os 16 núcleos do seu servidor estiverem ociosos o suficiente para que todos possam ser usados para compactação, pbzip2 provavelmente lhe dará uma aceleração muito significativa. Mas você precisa de mais velocidade ainda e pode tolerar arquivos ~ 20% maiores, gzip é provavelmente sua melhor aposta.
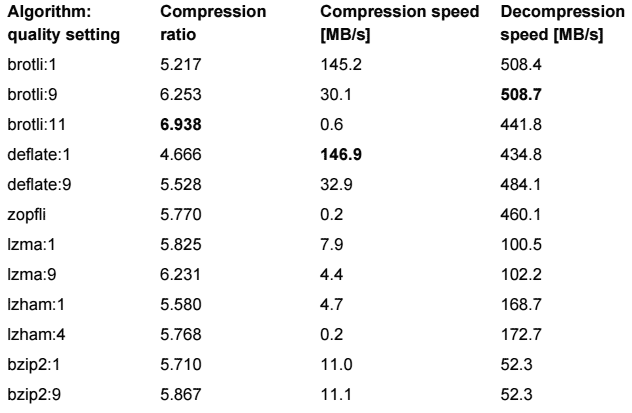
Atualização: adicionei os resultados de brotli (consulte a resposta do TOOGAMs) à tabela. A configuração da qualidade de compactação brotli s tem um impacto muito grande na taxa de compactação e na velocidade, portanto, adicionei três configurações ( q0 , q1 e q11 ). O padrão é q11 , mas é extremamente lento e ainda pior que xz . q1 parece muito bom; a mesma taxa de compressão que gzip , mas 4-5 vezes mais rápido!
Atualização: Adicionamos lbzip2 (veja o comentário do gmathts) e zstd (comentário do Johnny) à tabela e classificamos por velocidade de compactação. lbzip2 coloca a família bzip2 de volta na corrida, comprimindo três vezes mais rápido que pbzip2 com uma excelente taxa de compactação! zstd também parece razoável, mas é batido por brotli (q1) na proporção e na velocidade.
Minha conclusão original de que plain gzip é a melhor aposta está começando a parecer quase boba. Embora para onipresença, ainda não pode ser batida;)
{kind=link}
{kind=link}