Usando sed :
sed -E 's/((^| )2:)[^ ]*//g' in > out
Além disso, conforme inspirado na resposta do souravc , se houver não a chance de um 2: substring após o início de uma string not contendo uma substring 2: inicial (por exemplo, existe não uma chance de uma string 1:202:25 , que a seguinte encurtada comando substituiria para 1:202:0 ), o comando pode ser encurtado para isto:
sed -E 's/2:[^ ]*/2:0/g' in > out
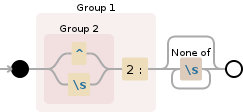
Resumo do Comando # 1 / # 2 :
-
-E: tornasedintepret o padrão como um padrão ERE (expressão regular estendida); -
> out: redirecionastdoutparaout;
% de falha do comandosed # 1 :
-
s: afirma para executar uma substituição -
/: inicia o padrão -
(: inicia o grupo de captura -
(: inicia o agrupamento das strings permitidas -
^: corresponde ao início da linha -
|: separa a segunda string permitida -
: corresponde a um caractere -
): para de agrupar as strings permitidas -
2: corresponde a um caractere2 -
:: corresponde a um caractere: -
): pára o grupo de captura -
[^ ]*: corresponde a qualquer número de caracteres que não seja -
/: interrompe o padrão / inicia a sequência de substituição -
: backreference substituído pelo primeiro grupo de captura -
0: adiciona um caractere0 -
/: interrompe a sequência de substituição / inicia os sinalizadores de padrão -
g: afirma para executar a substituição globalmente, ou seja, para substituir cada ocorrência do padrão na linha
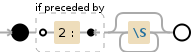
% de falha do comandosed # 2 :
-
s: afirma para executar uma substituição -
/: inicia o padrão -
2: corresponde a um caractere2 -
:: corresponde a um caractere: -
[^ ]*: corresponde a qualquer número de caracteres que não seja -
/: interrompe o padrão / inicia a sequência de substituição -
2:0: adiciona uma2:0string -
/: interrompe a sequência de substituição / inicia os sinalizadores de padrão -
g: afirma para executar a substituição globalmente, ou seja, para substituir cada ocorrência do padrão na linha